A inteligência artificial na saúde está avançando rápido — mas junto com os benefícios, surgem riscos sérios: alucinações, respostas imprecisas e decisões clínicas potencialmente perigosas. Para enfrentar esse desafio, ganha destaque o RAG (Retrieval-Augmented Generation), uma técnica que torna os sistemas de IA mais seguros, rastreáveis e baseados em evidência.
Diferente de modelos que apenas “lembram” o que foi treinado, o RAG busca informações confiáveis em tempo real, como diretrizes clínicas e artigos científicos, e gera respostas contextualizadas com base nesses dados.
Neste artigo, você vai entender como o RAG funciona na prática, por que ele reduz alucinações em IA médica e como hospitais e startups já estão usando essa tecnologia para apoiar decisões clínicas com mais confiança.
Funcionamento do RAG na prática
Vamos simular o caso de um hospital universitário que queira oferecer uma ferramenta para médicos e residentes realizarem pesquisas clínicas com apoio de IA, baseada em diretrizes, artigos científicos e protocolos internos.
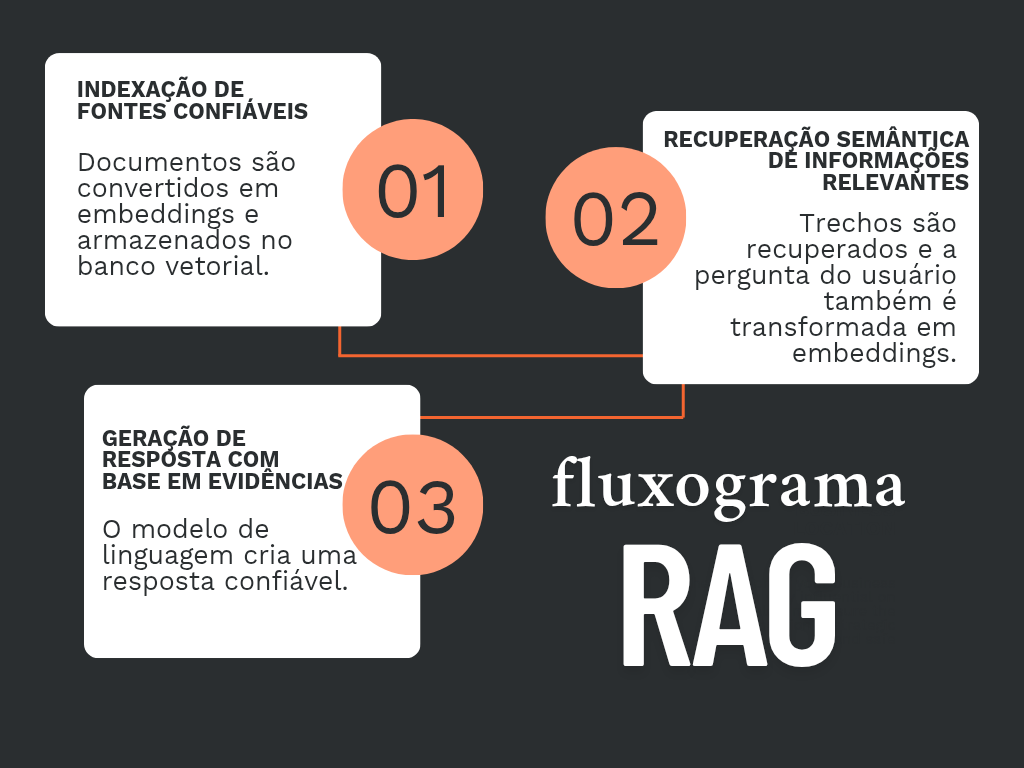
Etapa 1 – Indexação de fontes confiáveis
O hospital reúne e prepara os documentos que servirão como base do conhecimento:
- Diretrizes da Sociedade Brasileira de Cardiologia (SBC), Sociedade Brasileira de Neurocirurgia (SBN), American Heart Association (AHA), Organização Mundial da Saúde (OMS)…;
- Artigos científicos validados (PubMed, SciELO, NEJM…);
- Protocolos institucionais e manuais internos;
- Dados públicos de estudos clínicos.
Esses textos são convertidos em “embeddings”, que são vetores matemáticos que representam o conteúdo semântico. E são armazenados nos chamados bancos vetoriais, que serão os repositórios dos documentos.
Etapa 2 – Recuperação semântica de informações relevantes
O médico acessa a ferramenta de IA integrada ao prontuário ou suporte de apoio clínico, e pergunta, por exemplo: “Há evidências de que metformina reduz risco cardiovascular em pacientes diabéticos acima de 65 anos?”.
- O sistema também transforma essa pergunta em um embedding;
- Faz uma busca vetorial no banco de dados;
- Recupera, nos documentos anexados, os trechos, relacionados à pergunta do usuário, mais relevantes, como:
- Trecho de uma diretriz da Sociedade Brasileira de Diabetes (SBD);
- Resumo de um estudo de coorte da revista científica The Lancet;
- E nota de um protocolo institucional do próprio hospital.
Todo o conteúdo vem do material indexado, o que reduz risco de alucinação factual.
Mas isto ainda não é a resposta. A resposta será gerada na próxima etapa.
Etapa 3 – Geração da resposta com base nas evidências encontradas
O modelo de linguagem (como GPT-4, Claude, LLaMA, etc.) recebe:
- A pergunta original;
- Os trechos mais relevantes como contexto (em prompt).
E então a resposta, natural, coesa e referenciada, é gerada, como:
“Sim, há evidências de que a metformina pode reduzir eventos cardiovasculares em idosos com DM2. Um estudo publicado no Lancet (2022) com 12 mil pacientes mostrou redução de 18% no risco relativo. A diretriz da ADA 2024 também recomenda seu uso como primeira linha nesse perfil de paciente.”
A resposta vem com citações clicáveis ou rastreáveis. E, então, o profissional tem acesso a um conteúdo clínico confiável, explicável e útil para a decisão médica.
Exemplos de Uso
ChatEHR
- Quem desenvolveu: desenvolvido internamente pela Stanford Medicine;
- Onde está sendo utilizada: no Stanford Health Care, em fase piloto, por 33 médicos, enfermeiros e assistentes clínicos;
- Pra quê serve: ferramenta de inteligência artificial generativa criada para permitir que médicos e profissionais de saúde interajam com prontuários eletrônicos (EHR) em linguagem natural;
- Como o RAG é aplicado: ao receber uma pergunta, como “o paciente tem alergia?”, o sistema localiza trechos dos registros clínicos do paciente, e alimenta o modelo de linguagem. Assim, são geradas respostas rastreáveis, auditáveis e contextualizadas.
Para mais informações sobre a ferramenta, acesse Stanford Medicine.
IntelliDoctor.ai
- Quem desenvolveu: desenvolvido por Roberto Shimizu (CEO e Chief AI Officer), Euclides Cavalcanti (Chief Medical Officer), e Braulio Bonoto (COO);
- Onde está sendo utilizada: disponível globalmente mediante assinatura;
- Pra quê serve: é um sistema de suporte à decisão clínica voltado a médicos e profissionais da saúde;
- Como o RAG é aplicado: ao receber uma pergunta sobre doença, medicamento ou qualquer outro assunto da área médica, o sistema localiza trechos de bases acadêmicas públicas e privadas, e alimenta o modelo de linguagem. Assim, são geradas respostas embasadas e rastreáveis.
Para mais informações, acesse IntelliDoctor.ai.
Benefícios do RAG
Transparência e confiabilidade
Artigo publicado, em 5 de julho, na npj Digital Medicine, avaliou se a aplicação da técnica RAG pode melhorar o desempenho de um modelo de linguagem local leve (Llama 3.2‑11 B) em consultas radiológicas sobre agentes de contraste iodados. E os resultados demonstraram 0% de alucinação em modelos com RAG, contra 8% em modelos sem. E o modelo com RAG demonstrou também significativa melhora nas respostas.
Ou seja, menos alucinações, combinado com referências que são fornecidas ao gerar a resposta, oferece mais transparência e confiabilidade.
Atualização contínua, sem necessidade de retreinamento
Modelos pré-treinados necessitam que sejam adicionados mais dados à sua base de conhecimento. Ao utilizar RAG, o sistema recupera informações atualizadas de bases confiáveis e as insere no prompt, sem necessidade de retreinamento.
Privacidade e compliance
RAG pode rodar localmente, evitando envio de informações pessoais de saúde para a nuvem, e atendendo HIPAA/LGPD.
Menor custo
Realizar o retreinamento de um modelo pré-treinado, para mantê-lo atualizado, é um processo custoso e demorado, pois exige técnicas extensivas de etiquetagem e curadoria de dados, além de alto consumo de poder computacional. Em contraste, modelos com RAG permitem a incorporação de novos documentos e diretrizes diretamente na base de conhecimento, dispensando a necessidade de novo treinamento.
Limitações
Qualidade do repositório
Se os documentos estiverem desatualizados ou mal estruturados, o modelo poderá gerar respostas incompletas, despadronizadas e potencialmente incorretas. Por isso, é fundamental manter o repositório organizado e atualizado.
Maior latência
A utilização de modelos de linguagem com RAG aumenta a latência e pode degradar a experiência do usuário, embora algumas medidas possam minimizar este problema.
Técnica RAG em alta
Alguns fatores explicam o porquê do RAG estar tão em alta:
- Alucinação virou assunto regulatório: órgãos reguladores cobram rastreabilidade, e empresas mais sensíveis à erros, como das áreas de finança e saúde, tem evitado utilizar inteligência artificial generativa por conta das alucinações;
- Amazon Bedrock e outros serviços de nuvem simplificaram a integração: hoje é muito mais simples gerenciar um serviço de IA generativa. O Amazon Bedrock, plataforma da Amazon Web Services (AWS), por exemplo, oferece acesso a diversos modelos de LLMs, integra bancos vetoriais com ingestão automática de documentos, e sem expor dados ao modelo.
- Casos clínicos de alto impacto: cases de sucesso, como o ChatEHR, tem chamado atenção de gestores, que demonstram mais interesse por este tipo de solução.
Acesse e acompanhe a explicação de outros termos relacionados à inteligência artificial, no nosso glossário de IA médica: Neural Explica!
📚 Referências
Sites Oficiais
Artigos Científicos
Reportagens e Conteúdo de Mídia
Postagens em Redes Sociais
— 🧠 **Por Gustavo Giannella, para o Neural Saúde** Biomédico especialista em diagnóstico por imagem e inteligência artificial aplicada à saúde. Editor do portal NeuralSaude.com.br, dedicado a mapear e explicar como a IA está transformando a medicina no Brasil. 📩 Quer acompanhar as novidades? Siga o [Instagram @neural.saude] ou visite o site [www.neuralsaude.com.br] —